- 80% of outreach replies are repetitive ("how much", "how does it work", "send me a case"). AI can close these.
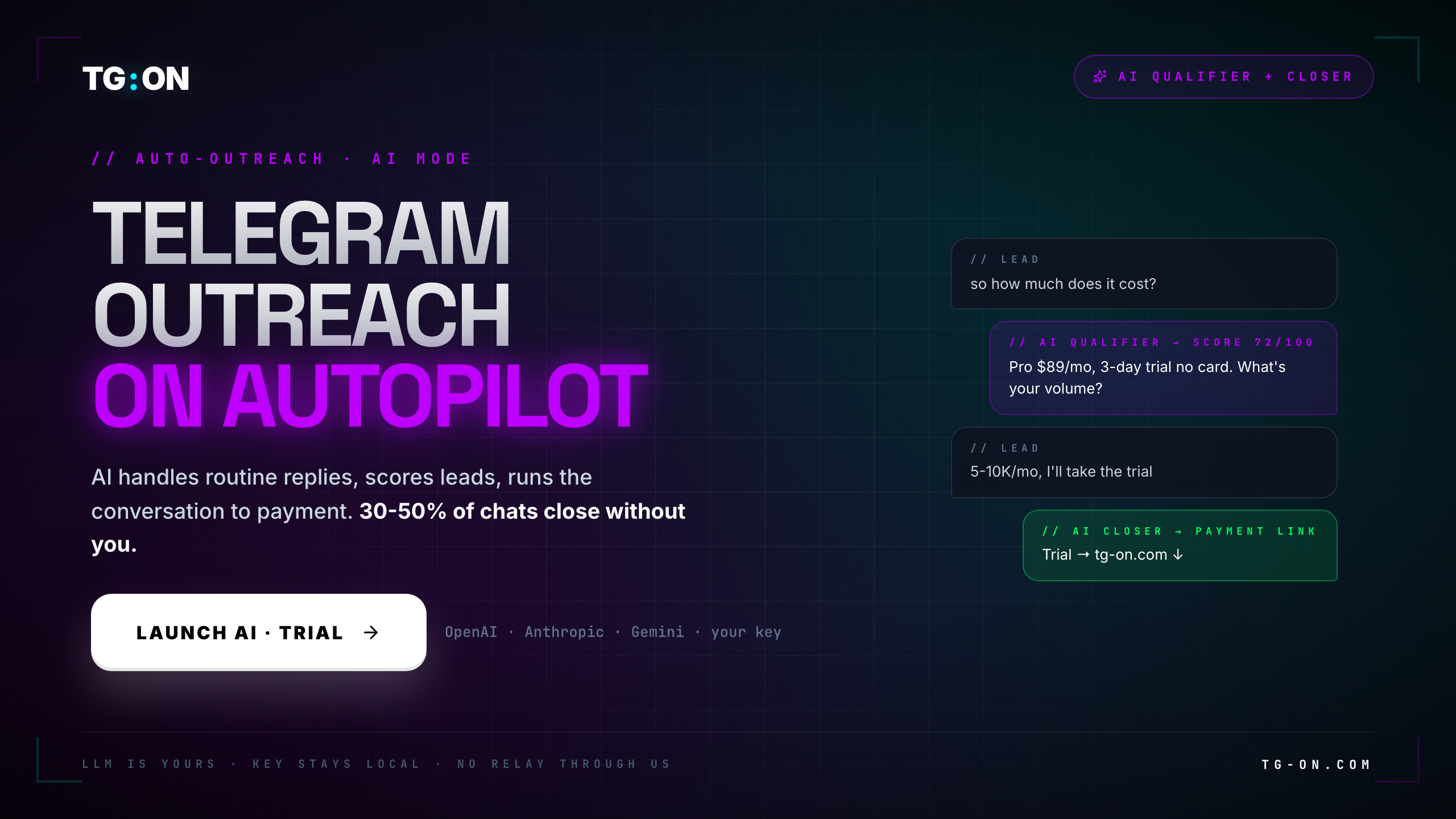
- TG:ON AI Agents: Qualifier scores leads 0-100 → on "ready to buy" signal, handoff to Closer who drives the deal to payment.
- LLM — your choice: OpenAI / Anthropic / Gemini / DeepSeek / Groq. Keys stay local, never touch our server.
- Response latency 45s–3min (human-like). Not instant — the model doesn't give itself away.
- Hard-stop keywords (refund, complaint, lawyer) → AI stops, the conversation goes to a human. Safety is priority.
- Pilots: 30-50% conversations auto-closed, 15-25% auto-qualified, 20-40% human takeover. Variance by niche.
Run the math: you launch cold outreach to 1000 addresses, you get 150 replies. Out of those 150, 120 are three recurring questions: "how much", "how does it work", "do you have a case study". And 30 are "not interested / unsubscribe". Real human work hidden in there — maybe 10 conversations, the rest is mechanical Q&A.
The problem is that a human still spends 5-8 hours on those 150 replies. Opens each one, reads the context, replies in tone, doesn't mix up leads. Meanwhile new replies pile up, response goes out 6 hours later, the lead has already cooled off.
TG:ON's AI Agents solve exactly that problem. They don't "replace sales" — they take 80% of the routine off your plate and hand the human only those 10-20 conversations where a human is actually needed. Below — how it's built under the hood.
The difference between SaaS-chatbot and LLM-based agent
When people say "AI for sales", 90% picture Intercom/Drift — scripted decision trees: "if user wrote X → reply Y". That's not AI, that's if-else with a UI. Works on FAQ, breaks on any non-standard question.
An LLM-based agent works differently. It reads the whole conversation context (last 20-30 messages + lead metadata), reasons via a system prompt, and generates the reply from scratch every time. If the lead asks "do you have a Notion integration?" — Qualifier isn't matching that to a tree, it just knows the product from its system prompt and answers on point.
Concrete example:
The difference is tangible. The lead just closes the first reply. The second one continues the conversation, because they got a real answer plus a follow-up question that moves the funnel.
How Qualifier scores a lead
Qualifier is the first agent in the pipeline. Its job: read the incoming reply, understand the lead, assign a score. Here's how:
- Context window: last 20-30 conversation messages + metadata (lead source, channel, previous outreach text, time of first contact).
- Scoring signals: intent (are they clearly interested), budget (did they mention money / "how much"), timeline ("now / next month / later"), role (do they decide themselves or "I'll ask the team").
- Output: score 0-100 + tags (
hot/warm/cold), plus a recommendation: auto-reply / handoff to Closer / escalate to human.
Scoring formula (simplified):
In FAQ-mode, Qualifier answers standard questions itself: pricing, basic tech questions, how to start a pilot. If a question is beyond its competence — escalates further down the pipeline.
Conversation handoff and deal closing
When Qualifier tags hot, the conversation is seamlessly handed to Closer. From the lead's perspective — nothing changes: same tone, same account. Under the hood, what changes is the system prompt and the loaded context: Closer gets the full pricing sheet, case studies, and payment flow.
Example conversation where Qualifier handed off and Closer picked up:
Closer doesn't "push". Its system prompt includes a rule not to pressure: if the lead says "too expensive", it offers Starter ($49); if "not right now" — it politely closes the conversation with an offer to return in 2-3 weeks. On clear buying signals ("I'll take Pro", "let's get it going") — it sends a payment link and flags the conversation as closed_won.
Latency tuned to human. Replies aren't instant — random 45s–3min interval plus a "typing" indicator. The model doesn't give itself away by speed. The lead doesn't feel they're talking to a machine — and even if they suspect, they can't prove it.
Five providers, different trade-offs
TG:ON isn't locked to one LLM. You pick the provider and plug in your API key — it's stored locally on your machine, never goes through our server. Comparison:
| Provider | Strength | Weakness | ~$ / 1K messages | When to pick |
|---|---|---|---|---|
| OpenAI (GPT-4o) | Best dialog quality, confident reasoning | Pricier than the rest | $2.50–5.00 | High-ticket ($500+), every deal matters |
| Anthropic (Claude) | Best safety, careful tone, less hallucination | Price close to OpenAI | $2.00–4.50 | Regulated niches (fintech, health), sensitive audiences |
| Gemini (2.0 Flash) | Great price/quality ratio, long context | Tone can be "dry" | $0.50–1.20 | High volume (10K+ conversations/mo), mid-ticket |
| DeepSeek | Ultra-cheap, solid quality on RU | Weaker on non-standard questions | $0.15–0.40 | Mass B2C, low ticket, RU market |
| Groq (Llama 3.3) | Fastest (200+ tokens/s), OSS model | Shorter context, needs prompt tuning | $0.30–0.80 | When latency is critical (Groq + artificial UI delay) |
Typical pilot setup: Claude for Closer (closing quality matters) + DeepSeek/Gemini for Qualifier (higher volume, quality less critical than at closing). Economics — 3-5× cheaper than "everything on GPT-4o" with comparable end result.
When AI goes silent and calls a human
An AI talking to a real customer is risk. One hallucination ("we offer a 60-day money-back" when in reality it's 14) = legal problem. That's why Qualifier/Closer have a hard-layer of hard-stops built in:
- Keyword blacklist:
refund,complaint,lawyer,police,sue,contract,GDPR,chargeback,threat. Any of these in a lead's message → AI stops immediately, conversation status goes toescalated, operator is notified. - Intent detection for financial topics: if the lead talks about refunds / complaints / competitor comparison in the format "you promised X, got Y" — auto-escalates, even without an exact keyword match.
- Max N turns: by default, AI runs a max of 15 messages in a single conversation. After 15 — soft handoff to human ("want to make sure you get the right answer — passing you to a colleague").
- Confidence threshold: if the LLM itself returns an answer with low confidence (model signal on uncertainty) — we don't send it, ask a human to review.
Escalation flow visualized:
Numbers, not promises
Through 2025-2026 we ran Qualifier+Closer on 40+ pilots — from B2B SaaS to infoproducts, 2 fintech clients. Median numbers:
Variance by niche:
- Infoproducts / courses: 45-50% auto-closed (FAQ-driven dialog, few nuances, AI handles it).
- B2B SaaS ($50-200 ticket): 35-40% auto-closed (more feature Q&A, but Closer carries through).
- B2B Enterprise ($1K+): 15-20% auto-closed (many stakeholders, AI only scores, human closes).
- Fintech: 10-15% auto-closed (regulatory, many hard-stops, AI mainly pre-qualifies).
We don't promise AI closes everything. In some niches, AI is just the first filter, and the deal is driven by a human. That's fine. The point is to kill the routine, not replace the sales director.
TG:ON for macOS · Windows · Linux
Desktop app, 160 MB. Runs locally, your keys stay yours. 3-day trial, no credit card.
Download for freeQualifier + Closer
in the Pro tier.
Your LLM key. Local. No relay through us. Pilot on 100 conversations during trial — see if it fits.
Start trial