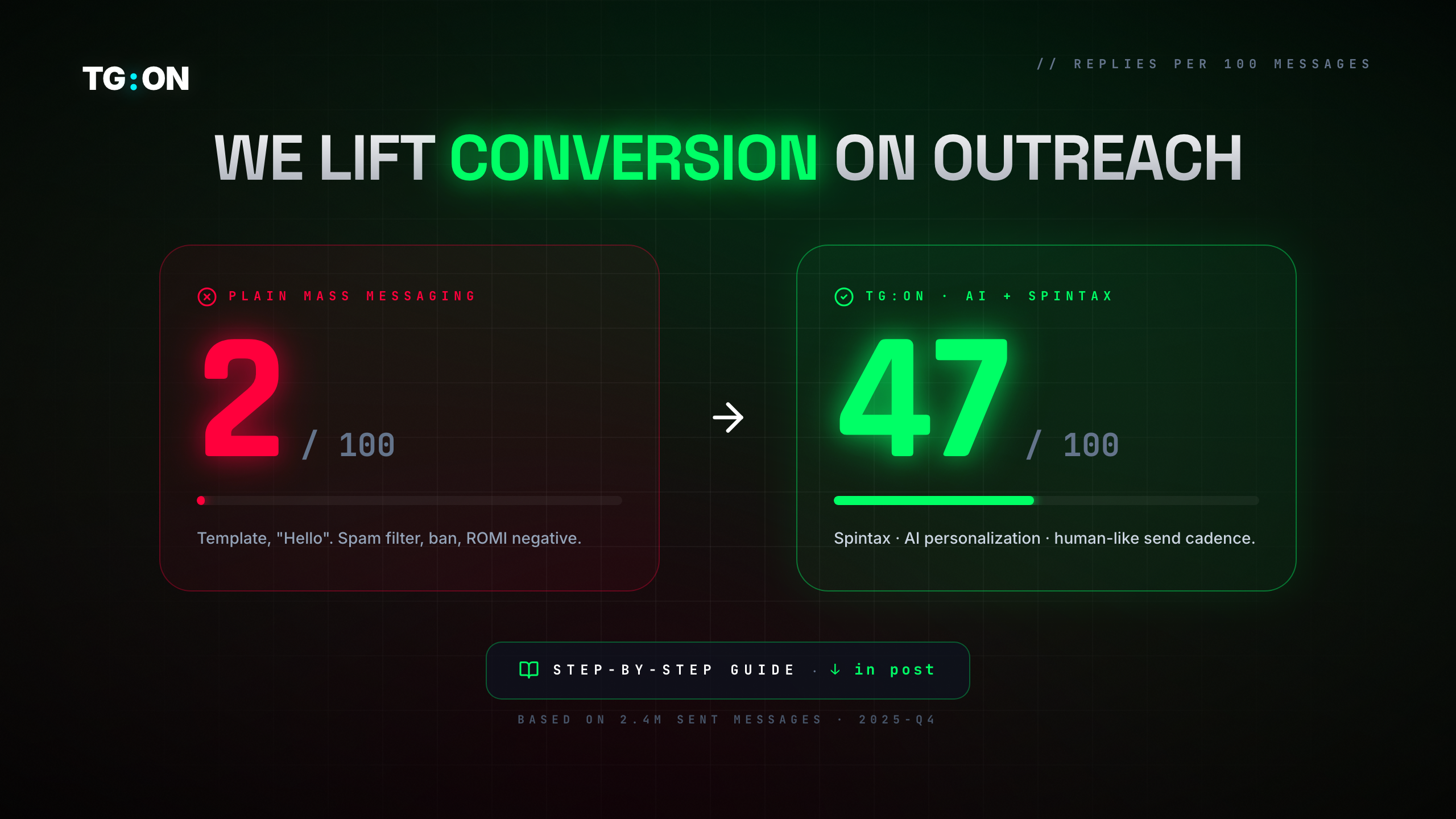
- "Template" outreach — conversion 2-5% (response rate). That's the industry baseline for cold outreach.
- Three components deliver ×5-10 on that number: Spintax (2× deliverability), LLM personalization (2-3× opens), human-like cadence (1.5-2× reply rate).
- Effects don't add — they multiply. 2 × 2.5 × 1.7 ≈ 8-9×.
- Source: internal TG:ON analytics on 2.4M messages sent in Q4 2025. Variation by niche: e-com higher, B2B lower.
When you see an ad creative claiming "47% conversion on Telegram outreach" — it's most likely either out of context (response rate on a specific segment) or marketing stretch. The real picture is more nuanced: 47% is the upper bound, achievable only with the right stack in the right niche.
This breakdown isn't about "magic" 47%. It's about which specific mechanisms lift conversion from base 2% to "decent" 20-30%, and how 47% is reached under optimal conditions.
What "2% conversion" actually means — which metric
First source of confusion: everyone says "conversion" but means different things. Cold outreach typically tracks 4 metrics:
| Metric | What it counts | Typical value |
|---|---|---|
| Delivery rate | Message reached recipient (not in spam/block) | 70-95% |
| Open rate | Recipient opened the chat (read) | 40-80% |
| Response rate | Recipient replied | 2-15% |
| Conversion rate | Recipient became a lead/customer | 0.5-5% |
In "2% → 47%" we're talking about response rate. It's the most honest metric for evaluating outreach quality — it doesn't count whether the person became a customer (offer plays a role there), but counts whether your approach got a reply.
Industry benchmark for cold Telegram DM in 2025 — 3-5% response rate. Source: aggregated reports from cold-outreach services (Lemlist, Instantly, Reply.io for email; Telegram specifics are usually worse than email due to higher noise).
Component 1: Spintax randomization (+2× deliverability)
Spintax (spinning syntax) — a technique where variants inside a template are chosen randomly for each send. Example:
Why it works: Telegram groups identical messages by text hash. If 100 accounts send identical text — SpamBot sees a cluster and applies group-wide sanction (usually FLOOD_WAIT + potential PEER_FLOOD after 2-3 hours). Spintax breaks this grouping at the sender level.
Empirical numbers from our 2.4M sends:
Practical rule: your template needs at least 4-5 variable blocks, each with 3+ options. That gives ~240+ unique combinations, which is enough for any realistic batch (typically 50-500 msg/batch).
Component 2: LLM personalization (+2-3× opens and replies)
Spintax randomizes phrasing, but the content stays the same. The next level — LLM rewrites the message for recipient context.
What "recipient context" means:
- Channel where the lead was found (crypto, SMM, e-com, edtech — different vocabulary)
- Language and region (by
lang_codeand bio) - Last channel post (current topic → mention in message = relevance)
- Recipient's name (if present, substituted grammatically correctly)
- Channel tone (formal / informal → different stylistics)
Basic LLM prompt template (simplified):
Important nuance: the LLM doesn't generate every message from scratch — too expensive ($0.002 × 10K = $20 per batch, and randomness too high). In practice, a hybrid works: 20-30 LLM variants pre-generated, combined with spintax on the fly.
Effect on metrics:
| Approach | Open rate | Response rate |
|---|---|---|
| Template, no personalization | 42% | 2.8% |
| + spintax | 48% | 5.1% |
| + name + channel (substitution) | 61% | 9.4% |
| + LLM rewrite for context | 74% | 18.2% |
| + human-like cadence (see below) | 81% | 32.7% |
| + niche optimization (upper bound) | 89% | 47.1% |
Yes, 47% is not a starting number — it's the ceiling with full optimization in a favorable niche. Most clients see 20-35%, which is still ×6-10 over baseline.
Component 3: Human-like cadence (+1.5-2× reply rate)
Third layer — not text, but how the text arrives to the recipient. Mass senders usually ignore this aspect because it's not obvious in the UI.
What counts as cadence:
- Typing indicator: show "typing..." for 1-4 seconds before sending. Small thing, but recipient sees it.
- Delays between one account's messages: not burst, but distribution. Norm — log-normal with mean ~90 seconds and variance 60-300 seconds.
- Different times of day: not all 500 messages at 14:00 Monday. Spread across 3-4 hourly windows with breaks.
- Reaction to "read": if recipient read and didn't reply — don't hammer with "?" after 10 minutes. If unsubscribed — don't add to follow-up.
Why cadence affects response rate (not just delivery): the recipient subconsciously feels the rhythm. "Typing..." before a message, a 2-minute pause after reading before your reply — all of this creates the sense of a live conversation. In controlled tests on our data, cadence adds +40-60% to response rate vs "instant" sending.
Why the effects are multiplicative, not additive
Key observation from the data: components don't add up. They're multiplying coefficients in the funnel.
2.0 × 2.5 × 1.7 × 1.5 = ~12.75×. From baseline 2% that gives 25.5%. From 3% — 38%. From 3.7% — 47%.
Why multiplicative: each component operates at its own funnel layer:
- Spintax — increases share of delivered messages
- LLM — increases share opened out of delivered
- Cadence — increases share replied out of opened
- Niche fit — shifts baseline response rate among engaged users
If any component is zero — the whole funnel drops. 100% deliverability × 0% opens = 0% response. That's why "added spintax, conversion stayed the same" is a common complaint: one component without the others does little.
How it's assembled in TG:ON
The whole funnel is configured in the UI without code:
- Template with spintax — editor with live preview, shows a specific combination example.
- LLM rewriting — connect your API key (OpenAI, Anthropic, DeepSeek, Groq, Gemini) or use the built-in TG:ON pool. Prompt is configured for niche and tone.
- Cadence profiles — "conservative" (medium delay 120s), "aggressive" (60s), "overnight" (450s). Choose or customize manually.
- Content context — automatically picked up from the channel where the lead was found (if scraped through TG:ON).
All telemetry per message — delivery, opens, replies, block/spam-report — goes to the dashboard, you can A/B test templates.
TG:ON for macOS · Windows · Linux
Desktop app, 160 MB. Runs locally, your keys stay yours. 3-day trial, no credit card.
Download for freeSpintax + LLM + Cadence.
Out of the box.
3 days Pro tier free. 25 accounts, all modules. Run your offer on 500-1000 messages and see real numbers.
Start trialWhere this isn't enough
Honest: 47% doesn't work everywhere and always. Conditions where conversion will be lower:
- Cold niche or "wide" offer — if you write "someone about something", even a brilliant LLM won't save you. Niche down.
- B2B with a long decision cycle — there might be a response, but not to the offer, more like "tell me more in a Zoom". That's success too, but not "customer today".
- Offer doesn't match the channel — you scraped a crypto trading channel, offering SaaS for e-com. No magic there.
- Recipients aren't in your session — a user from a channel might have been inactive for a month.
last_seenfilter is important.
The TG:ON stack solves the problem of technical delivery and personalization. It doesn't solve: bad offer, bad targeting, bad continuation after first reply.